Transformer: The Brain of Large Language Models - Explained with a Library Analogy
3/9/2026
Have you ever wondered why ChatGPT can instantly answer your questions? Why Claude can write fluent articles? Why GPT-4 can understand images and write code?
Behind all of this lies a common “brain” — the Transformer.
In 2017, the Google team first proposed this architecture in the paper “Attention Is All You Need,” completely changing the trajectory of AI. Paper link:
https://arxiv.org/abs/1706.03762
Today, without formulas or jargon, we’ll break down this world-changing AI architecture in the most accessible way possible.
First, Let’s See What Transformer Can Do
Before diving into the principles, let’s feel the power of Transformer:
- Machine Translation: Input Chinese, output English
- Text Generation: Input “Once upon a time,” and it continues the story
- Code Completion: Input a function name, and it auto-completes the logic
- Question Answering: Input a question, get a precise answer
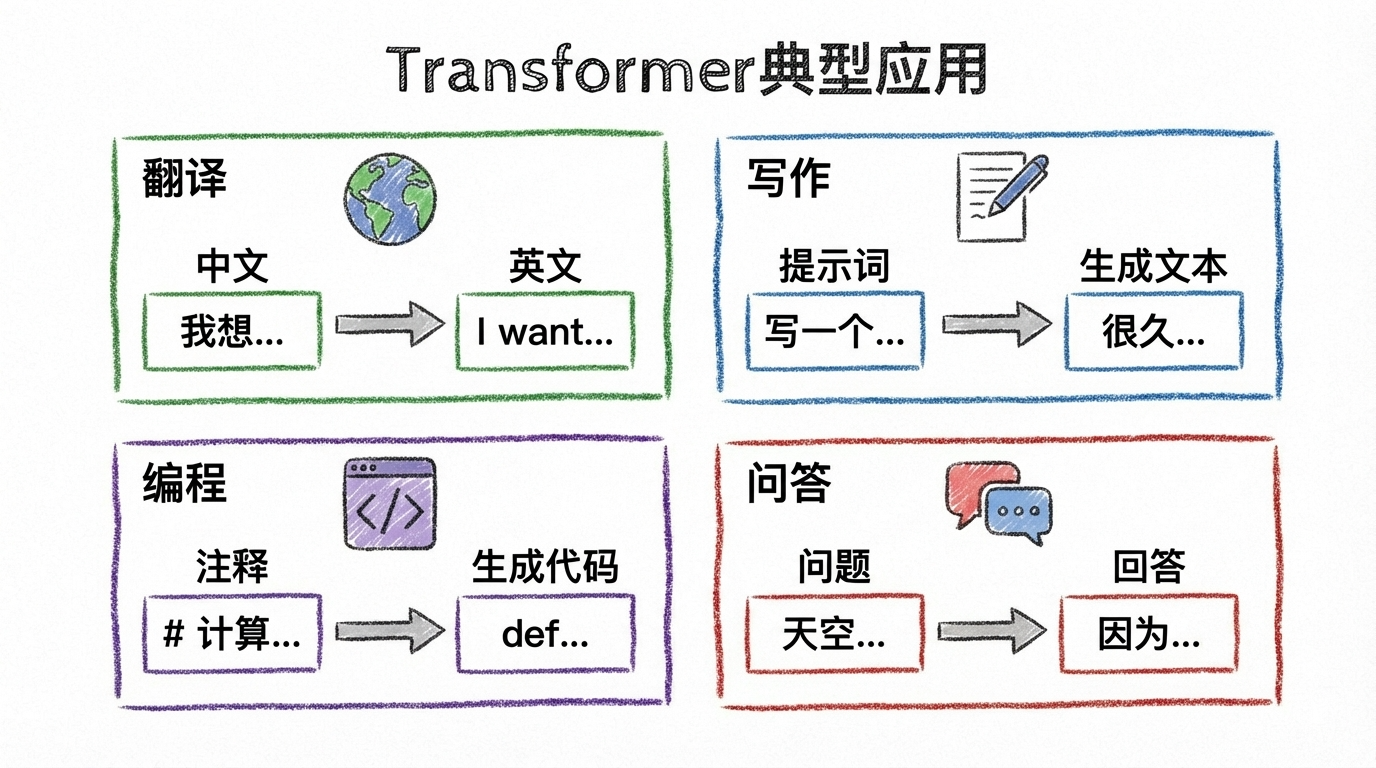
These tasks seem different, but their core is the same: Input text, output text.
So the question is: How does Transformer do it?
The Core Question: How Does AI “Understand” a Sentence?
Imagine you’re reading this sentence:
“Xiao Ming likes apples, he often goes to the supermarket to buy them.”
When you see the word “them,” your brain immediately knows “them” refers to “apples” not “Xiao Ming.” Why? Because you have “attention” — you know the action “buy” pairs better with “apples.”
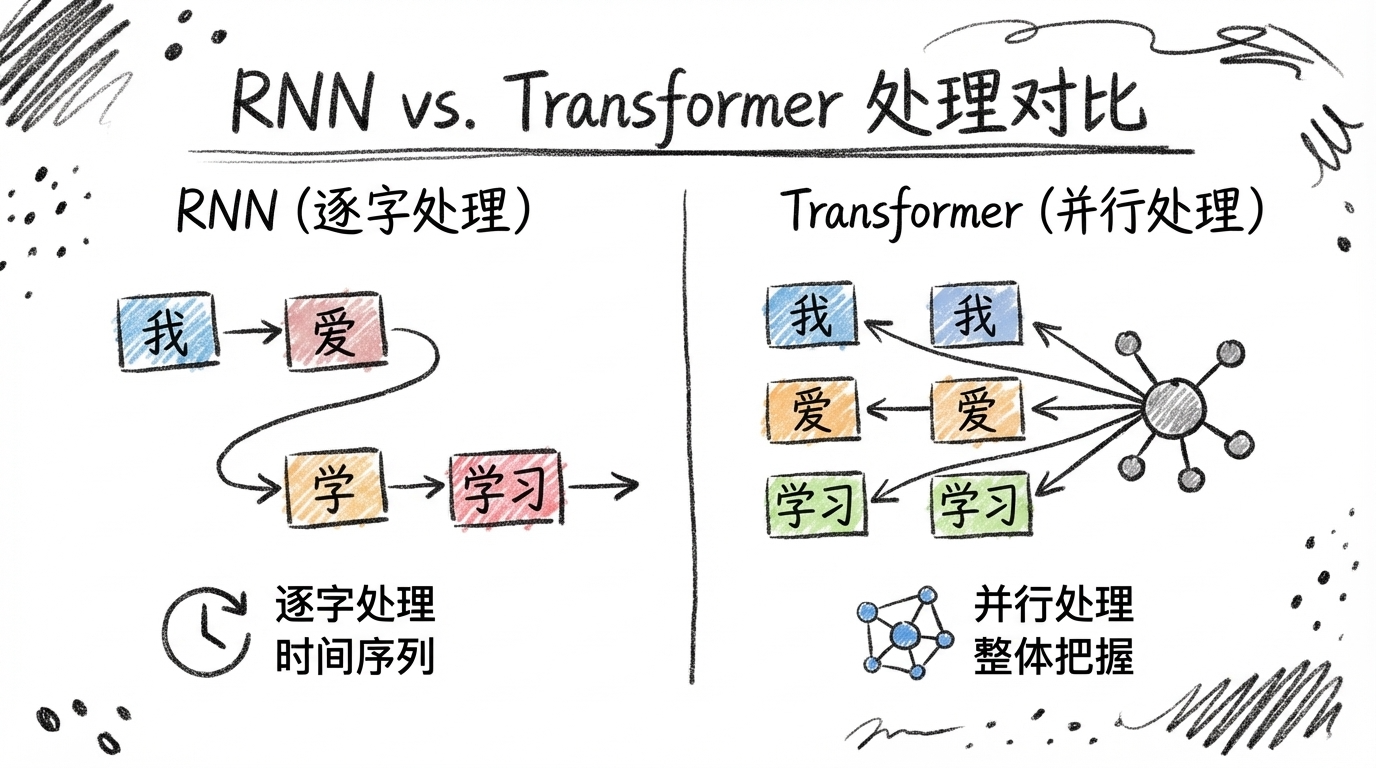
The Dilemma of Traditional AI: Early models (like RNNs) were like assembly line workers, processing one word at a time. By the time they reached “them,” they had already forgotten which “apples” came before. Long sentences caused information to “black out.”
Transformer’s Breakthrough: It doesn’t need to process word by word. Instead, it sees the entire sentence at once, then uses the “attention mechanism” to find relationships between words.
Core Principle: Attention Mechanism (Library Analogy)
The core of Transformer is the “self-attention mechanism.” Sounds mysterious? It’s actually exactly like going to a library to borrow books.
The Library Search Trio: Q, K, V
Suppose you want to find books in a library:
| Role | Library Scenario | In Transformer |
|---|---|---|
| Q (Query) | Your need: “I want books about AI” | What information the current word is looking for |
| K (Key) | Shelf labels: “Computer/AI/Machine Learning” | Feature labels of each word |
| V (Value) | The actual content of the book | The actual meaning of each word |
Workflow:
- Match Q with K: Compare your need (Q) with shelf labels (K) to find the most relevant shelves
- Retrieve V based on match level: The higher the match, the more important that book’s content (V) is to you
- Integrate all information: Combine the found books to form your answer
Real Example: The Story of “Apples” and “Them”
When the model processes “Xiao Ming likes apples, he often goes to the supermarket to buy them”:
The Q of “them” asks: “Who am I? What am I referring to?”
All words’ Ks answer:
- “Xiao Ming“‘s K: “I’m a person’s name”
- “likes“‘s K: “I’m a verb, expressing emotion”
- “apples“‘s K: “I’m a fruit, can be bought/sold”
- “supermarket“‘s K: “I’m a location”
Match Result: “them“‘s Q matches “apples“‘s K most highly (because “buy” and “fruit” pair reasonably)
Final Output: “them“‘s V incorporates “apples” information, the model understands “them = apples”
Transformer Architecture Diagram (Simplified)
Let this diagram help you instantly understand the overall Transformer architecture:
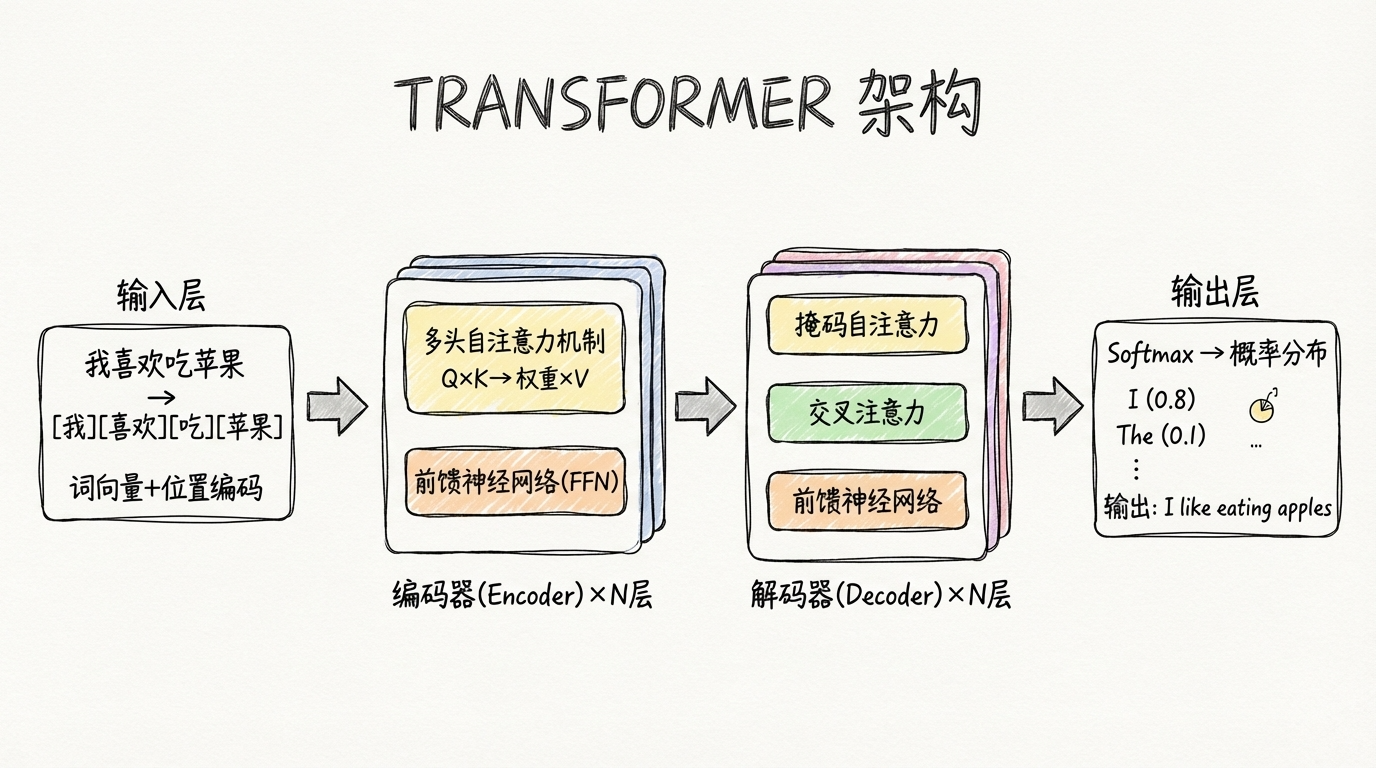
Three Key Components, Explained One by One
1️⃣ Word Embeddings + Positional Encoding
Problem: Computers only understand numbers. How do we turn “apple” into numbers?
Solution: Convert each word into a numeric vector (e.g., 768 dimensions). Similar words have similar vectors. “Apple” and “banana” vectors are close; “apple” and “car” are far apart.
New Problem: Transformer processes in parallel. How does it know word order?
Solution: Add “positional encoding” — give each position a unique marker, like numbering seats. The 1st word gets “position 1” marker, the 2nd word gets “position 2” marker…
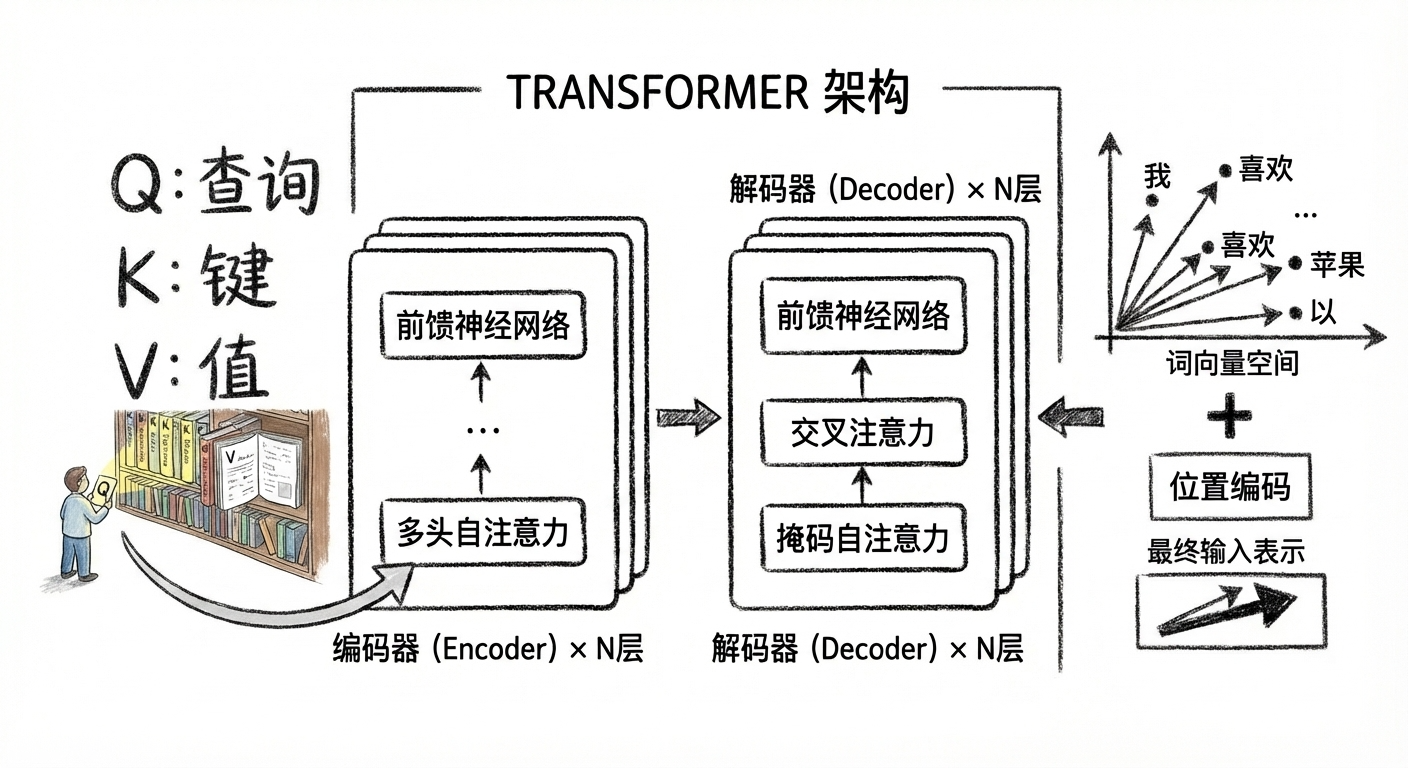
2️⃣ Multi-Head Attention
Problem: One attention head might not see the full picture.
Analogy: Like a group of people discussing a problem, each person focuses on different angles:
- Person A focuses on “grammatical structure”
- Person B focuses on “semantic relationships”
- Person C focuses on “contextual logic”
Solution: Use multiple “heads” simultaneously, each learning different relationships, then combine the results. GPT-3 uses 96 heads!
3️⃣ Feed-Forward Neural Network (FFN)
Function: After the attention layer, do a “deep think” independently for each word.
Analogy: The attention layer is responsible for “gathering information,” FFN is responsible for “digesting and absorbing.” Just like after reading a book, you need quiet time to organize your notes.
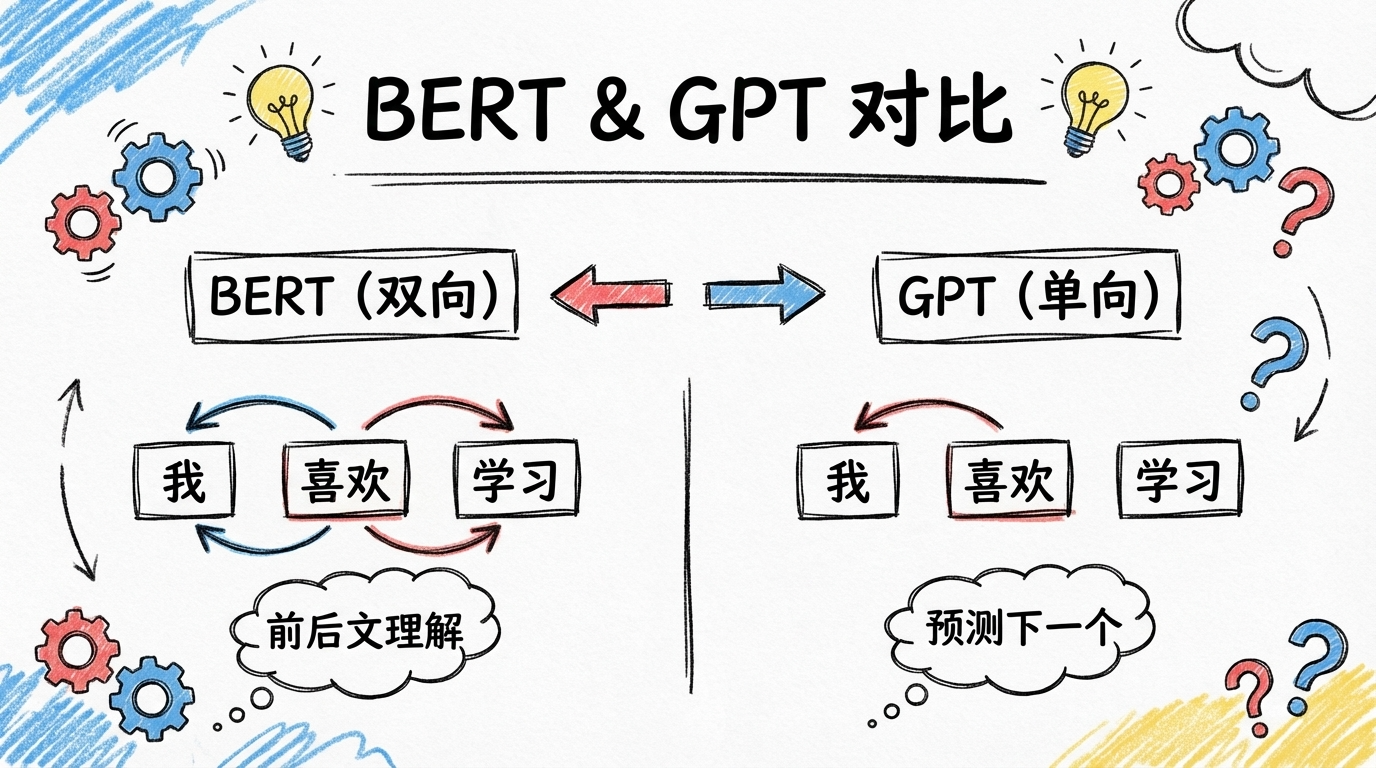
Why Does GPT Only Use the Decoder?
The original Transformer had both encoder and decoder parts, but the GPT series (including ChatGPT) only uses the decoder.
Why?
| Model | Architecture | Task | Characteristic |
|---|---|---|---|
| BERT | Encoder only | Understanding tasks (classification, QA) | Bidirectional, sees the whole sentence |
| GPT | Decoder only | Generation tasks (writing, dialogue) | Unidirectional, only sees previous words |
| Original Transformer | Encoder + Decoder | Translation tasks | Encoder understands, decoder generates |
GPT’s core task is “predict the next word,” so it only needs to look “left to right,” using masked self-attention to ensure it can’t peek at later words.
Summary: Transformer’s Three-Sentence Principle
-
Parallel Processing: Unlike RNN reading word by word, Transformer sees the entire sentence at once, much more efficient
-
Attention Mechanism: Using the Q, K, V trio, each word can find other words related to it
-
Layer-by-Layer Refinement: Through multiple encoder/decoder layers, continuously refine semantics and output results
Why Is Transformer So Powerful?
In one sentence: Because like the human brain, it can “simultaneously attend” to multiple pieces of information, rather than clumsily processing word by word.
This is why ChatGPT can have fluent conversations, Claude can write good articles, and GPT-4 can understand complex problems — they all stand on the shoulders of this Transformer giant.
Next time you use AI to write code, translate documents, or generate copy, remember to thank this brilliant architectural design.
Did you learn something? Feel free to share your understanding in the comments!
Welcome to follow the WeChat official account FishTech Notes to exchange ideas and experiences!