还在把 uv、npm、SSE、stdio 混为一谈?这次把 MCP 和 Spring AI 流式开发讲透
2026/3/12
前言
“怎么一个 MCP,能冒出 uv、npm、stdio、SSE 这么多词?”
很多人第一次看到配置页里的 SSE、Stdio,脑子会立刻打结:到底哪些是协议,哪些是命令,哪些又只是启动方式?再加上 Spring AI 开发里也总能看到 SSE,不少人很自然就会继续追问一句:这是不是就是所谓的流式开发?
今天这篇文章,我想把这几个最容易混淆的概念,一次性拆开讲透。你看完后,至少能分清三件事:uv/npm 是怎么回事,stdio/SSE 是怎么回事,Spring AI 里的”流式输出”和 SSE 到底是什么关系。
先说结论-一张图看懂
很多混乱,本质上是把”运行方式”和”通信方式”混在一起了。
| 你看到的词 | 它本质上是什么 | 解决什么问题 |
|---|---|---|
uv | Python 生态的工具/运行器 | 启动或安装 Python 写的 MCP Server |
npm / npx | Node.js 生态的包管理/运行工具 | 启动或安装 Node 写的 MCP Server |
stdio | 进程标准输入输出通信方式 | 让客户端和本地子进程通信 |
SSE | Server-Sent Events,HTTP 上的单向事件流机制 | 让服务端持续向客户端推送消息 |
| Streamable HTTP | MCP 官方当前主推的 HTTP 传输方式 | 让 MCP 通过标准 HTTP 传输,可按需配合 SSE 流式返回 |
一句话总结:uv/npm 不是 MCP 协议,stdio/SSE/Streamable HTTP 才属于传输层。
为什么大家总会混淆
因为在真实配置里,这些词经常同时出现。
比如一个本地 MCP Server 可能是 Python 写的,那客户端就会用 uv 去启动它;启动之后,客户端和这个子进程之间再通过 stdio 传 JSON-RPC 消息。
另一种情况是,MCP Server 独立跑在 HTTP 服务里,这时你看到的往往就不是 uv 或 npm 配置了,而是一个 URL。此时客户端和服务端之间走的是 HTTP 传输。这里要特别注意:MCP 官方替代的是旧版 HTTP+SSE transport 方案,不是说 SSE 这个技术本身被禁用了。 现在官方更明确推进的是 Streamable HTTP,而在这个新传输里,服务端依然可以按需使用 SSE 来承载流式消息。
也就是说:
uv/npm解决”这个服务怎么跑起来”stdio/SSE/HTTP解决”跑起来以后双方怎么通信”
这两个层次本来就不是一回事。
MCP 里的 stdio 到底是什么
stdio 是 standard input / standard output,也就是标准输入和标准输出。
在 MCP 里,它最典型的场景是:客户端拉起一个本地子进程,然后通过这个子进程的 stdin/stdout 交换 JSON-RPC 消息。
它的特点很鲜明:
- 特别适合本地工具型 Server,比如文件系统、Git、本地脚本类能力。
- 不需要额外开端口,部署简单。
- 对本地开发者体验很好,但天然偏”单机、本地进程”。
所以你在很多桌面客户端、IDE 插件、命令行工具里,经常能看到 stdio 配置。
SSE 到底是什么-它是协议吗
是,但更准确地说,SSE 是一种基于 HTTP 的服务器推送机制和数据格式约定,不是某个具体框架的专属实现。
SSE 全称是 Server-Sent Events。浏览器侧常见接口是 EventSource,服务端返回的内容类型通常是:
text/event-stream
它的核心特点只有两个:
- 连接会保持一段时间不关闭。
- 服务端可以持续往客户端推送事件。
所以如果你问”Spring AI 里用了 SSE,是不是就是流式开发?“更准确的回答应该是:
它通常是在做流式传输,但”流式”是能力,SSE 是承载这种能力的一种实现方式。
换句话说,流式输出可以用 SSE 做,也可以用 WebSocket、分块响应,甚至别的双向协议做。SSE 不是”流式”的同义词,只是 Web 场景里非常常见的一种方案。
Web App 或小程序里的版本更新推送-用的就是 SSE 吗
很多人理解了 “SSE 是服务端持续往客户端推送事件”,下一秒就会想到另一个常见场景:
那 Web App 或小程序里弹出来的”发现新版本,请刷新”提示,用的是不是也是 SSE?
答案是:有可能,但不一定。
因为”版本更新推送”是一个业务需求,SSE 只是实现它的其中一种方式,不是唯一答案。
在 Web App 里,SSE 确实可以做版本通知
比如你的前端页面一直开着,后端一旦检测到新版本发布,就可以通过 SSE 推送一条事件:
event: version-update
data: {"version":"1.2.0","message":"发现新版本,请刷新页面"}
浏览器收到后,前端就可以弹一个提示框,告诉用户刷新页面。
这类场景下,SSE 很顺手,因为它天生就是:
- 服务端单向推送
- 基于 HTTP,前端接入简单
- 很适合”通知类”消息
但很多项目并不会用 SSE
因为版本更新提醒对实时性的要求,通常没聊天消息那么高,所以很多团队会优先选更简单的办法:
- 每隔 30 秒或 1 分钟轮询一次版本号
- 页面启动时检查一次静态资源版本
- 如果项目本来就有 WebSocket 连接,顺手复用 WebSocket
- 如果是 PWA,则可能结合 Service Worker 做资源更新提示
所以你在 Web 项目里看到”新版本提醒”,不能直接推断它一定用了 SSE。
小程序场景更不能默认等于 SSE
到了小程序里,大家更常见的是:
- 启动时检查版本
- 请求接口获取配置
- 使用 WebSocket 做消息通知
- 直接依赖平台自己的更新机制
原因很简单,小程序运行环境不像浏览器那样天然围绕标准 Web API 设计,很多项目会优先选择平台更稳定、更通用的方式,而不是默认上 SSE 长连接。
所以更准确的说法应该是:
版本更新推送是一类业务场景,SSE 只是可选实现之一。
一句话记忆
你可以把它记成下面这个判断逻辑:
- 想要”服务端单向通知客户端”,SSE 可以用
- 想要”实现简单、兼容性高”,轮询也完全够用
- 想要”本来就有实时双向通道”,那就直接用 WebSocket
也就是说,看到”版本更新提示”,你应该先问的是”它怎么做更新通知”,而不是先假设”它一定用了 SSE”。
截至 2026-03-11-MCP 官方对 SSE 的态度是什么
这里有一个非常关键的时间点。
截至 2026 年 3 月 11 日,MCP 官方文档写得很明确:当前标准传输机制是 stdio 和 Streamable HTTP。 官方还特别说明,Streamable HTTP 是对旧版 HTTP+SSE transport 的替代。
这意味着两件事:
- 如果你在很多新文档里看到
Streamable HTTP,这是官方主线。 - 但这不等于 SSE 被弃用。在
Streamable HTTP规范里,服务端对一次POST请求,既可以直接返回application/json,也可以返回text/event-stream,也就是继续用 SSE 流式返回多条服务端消息。
所以别把”官方替代旧版 HTTP+SSE transport”理解成”官方禁止 SSE”。更准确的说法是:
- 被替代的,是 MCP 旧版 HTTP 传输方案
- 没有被否定的,是 SSE 作为流式承载机制本身
如果你在一些产品界面、SDK 或框架文档里还看到 SSE,通常只是因为它仍然是一个非常自然的流式输出手段。
Spring AI 里为什么总能看到 SSE
因为 Spring AI 本身就支持同步和流式两种编程模型。
官方文档里明确写了,ChatClient 既支持普通调用,也支持 stream() 返回 Flux<String> 这种流式模型。到了 Web 层,如果你想把模型逐段生成的内容持续推给前端,SSE 是一个非常顺手的选择:
- 后端拿到模型的 token/片段流。
- 服务端把这些片段不断写到 HTTP 响应里。
- 浏览器或前端客户端持续接收并刷新界面。
所以在 Spring AI 项目里,很多人会把”模型流式输出”最终落到 SSE 接口上。
但请注意这个层次关系:
- 模型是否流式生成,取决于模型接口和你的调用方式。
- 后端如何把流式结果发给前端,
SSE只是常见选项之一。
也就是说,Spring AI 的”流式开发”不等于 “SSE 开发”,而是”流式生成 + 某种流式传输”。只不过在浏览器场景里,SSE 成了默认感最强的答案。
Flux、SSE、WebSocket、Streamable HTTP 到底是什么关系
这一段是很多 Java 开发者最容易卡住的地方。
1. Flux 是编程模型,不是网络协议
在 Spring AI 里,ChatClient.stream().content() 返回 Flux<String>,意思是:你的代码拿到的是一个”会持续产生多个数据片段”的响应式流。
所以 Flux 回答的是:
- 你的代码怎么消费一串不断到来的数据
- 你的服务内部如何用响应式方式处理流
它不回答”这些数据最终通过什么网络格式发给前端”。
2. SSE 是 HTTP 上的流式输出格式
当你把 Flux 暴露给浏览器时,Spring WebFlux 可以直接返回 Flux<ServerSentEvent>,或者在 text/event-stream 响应下直接返回 Flux。Spring MVC 里也有专门的 SseEmitter。
所以在 Spring 技术栈里,最常见的链路其实是:
大模型流式输出 -> Spring AI 拿到流 -> 用 Flux 表达 -> Web 层以 SSE 发给浏览器
3. WebSocket 是另一种实时传输方案
如果你不想用 SSE,也完全可以用 WebSocket 来承载流式消息。它和 SSE 的区别在于:
- SSE 更偏”服务端持续推送给客户端”
- WebSocket 更偏”双向实时通信”
所以聊天场景不一定非得用 SSE,只是很多”AI 回答逐字输出”的页面,用 SSE 已经足够简单。
4. Streamable HTTP 是 MCP 的传输规范名
Streamable HTTP 不是 Spring AI 的概念,而是 MCP 协议里的传输定义。它规定的是:
- MCP 消息怎么通过 HTTP
POST/GET发送 - 客户端和服务端如何建立会话
- 服务端什么时候可以返回 JSON,什么时候可以返回 SSE 流
所以它和 Spring AI 的 Flux、SSE 并不是同一维度的东西。
一句话记忆
你可以这样记:
Flux:代码里的流SSE:HTTP 里的流WebSocket:双向实时通道Streamable HTTP:MCP 协议定义的一套 HTTP 传输规则,内部仍可使用 SSE
OpenAI 开了 stream=true-前端为什么还不一定是流式
这一点也特别容易让人误解。
很多人看到 OpenAI API 里有个 stream=true,第一反应会是:
“那我后端只要把这个参数打开,前端不就天然变成流式了吗?”
答案是:不一定。
因为这里至少有两段链路:
- 模型服务 -> 你的后端
- 你的后端 -> 你的前端
而 stream=true 只决定了第一段。
第一段:OpenAI 到后端,确实会变成流式
当你请求 OpenAI 并开启 stream=true 后,模型不会等整段内容都生成完再一次性返回,而是会把增量内容持续发给你的后端。
也就是说,这时变成流式的是:
OpenAI -> 你的后端
第二段:后端到前端,不会自动变成流式
如果你的后端代码虽然收到了上游流,但它选择:
- 先把所有内容拼完
- 再组装成一个普通 JSON
- 最后一次性
return
那前端看到的仍然是一个普通接口响应,而不是流式输出。
所以真正决定”用户界面是不是一个字一个字往外冒”的,不只是模型是否开启流式,还取决于:
- 后端有没有保留这条流
- 后端有没有把它继续以流式协议发给前端
Spring AI 帮你封装到了哪一层
Spring AI 做的事情,核心是把底层模型供应商的流式响应,统一抽象成 Java 侧的响应式流。
比如在 Spring AI 里,你经常会看到:
chatClient.prompt().user("你好").stream().content()
这一类调用最终返回的往往是:
Flux<String>
或者更完整一点的:
Flux<ChatResponse>
这说明 Spring AI 已经帮你把”模型流式输出”封装成了 Java 代码里的流。
Spring AI Alibaba 在这一层也是类似思路,本质上也是把模型增量输出包装成 Flux<?> 供你消费。
但 Flux 不等于前端已经拿到流式
这里非常关键:
Flux 只是后端代码中的流抽象,不等于浏览器已经在流式接收。
要让前端真正流式显示,你还得在 Web 层继续做一层输出,比如:
- 返回
text/event-stream - 直接返回
Flux<ServerSentEvent<?>> - 或者把
Flux<String>以 SSE 方式写回浏览器 - 或者改走 WebSocket
也就是说,Spring AI / Spring AI Alibaba 帮你封装的是:
- 模型厂商的流式协议
- Java 侧的统一流抽象
但它们不会替你自动决定:
- Controller 怎么暴露接口
- 前端到底走 SSE 还是 WebSocket
- 是保持流式,还是聚合后一次性返回
一张链路图看懂
你可以把整个过程理解成这样:
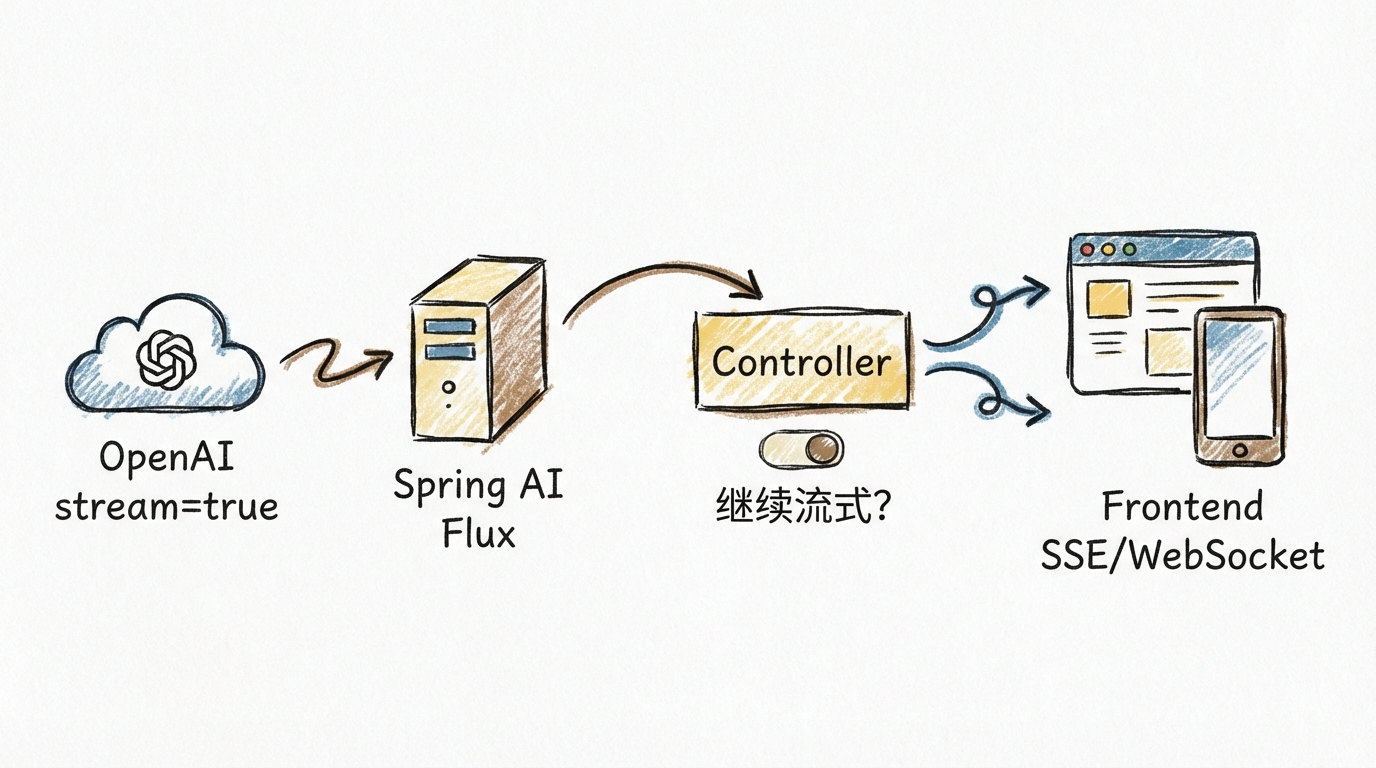
所以最后的准确说法应该是:
stream=true 只打通了”模型到后端”的流式链路;前端是不是流式,还要看后端接口是否也按流式方式输出。
为什么我明明已经用了 Flux-前端还是一次性返回
这几乎是 Spring AI 新手最常见的疑问。
很多人会说:
“我都已经 stream() 了,返回值也是 Flux<String>,为什么前端看到的还是最后一次性整段出来?”
问题通常不在模型层,而在 Web 输出这一层。
常见原因 1:你虽然拿到了 Flux,但又把它收集成了完整结果
比如有些代码会在中间做类似这种事情:
flux.collectList()
或者:
flux.reduce(...)
一旦你把流收集完再返回,本质上就已经把”流式”变回”一次性响应”了。
也就是说:
Flux是流collectList()之后就不再是逐段输出,而是等全部完成后再一起返回
常见原因 2:Controller 没有按流式方式往外输出
后端代码内部是 Flux,不代表 HTTP 响应天然就是流式。
如果你的接口只是普通 application/json 返回,或者没有按 text/event-stream 这类流式响应方式输出,很多前端环境会等到缓冲区积累完、甚至整个响应完成后才统一交给页面。
所以在浏览器场景里,更常见的写法是:
- 明确返回
text/event-stream - 或返回
Flux<ServerSentEvent<?>> - 或使用 WebSocket
常见原因 3:中间层把你的流缓冲了
有时候不是 Spring AI 的问题,也不是 Controller 的问题,而是链路中间有一层把流式响应”攒住了”。
常见场景包括:
- 网关缓冲
- Nginx/代理层缓冲
- 某些测试工具默认等完整响应
- 前端请求库没有按流式方式消费
所以你看到”一次性返回”,不一定代表后端没流式,也可能是中间链路把数据缓存后再吐给前端了。
常见原因 4:你用的是 Spring MVC 普通返回方式
如果项目是传统 Spring MVC,Controller 又按普通同步接口写法返回一个对象或字符串,那即使内部曾经经过 Flux,最终也可能在 MVC 层被聚合掉。
这也是为什么很多人会感觉:
“我项目里明明已经引入了 Spring AI,怎么前端还是不流?”
答案通常是:Spring AI 负责把模型输出封装成流,但你 Web 层没有把这条流原样往外送。
一条最实用的排查思路
遇到这个问题时,你可以从上到下只查 4 件事:
- 模型调用是不是开了流式,比如
stream=true - Spring AI 拿到的是不是
Flux<?> - Controller 是不是按
SSE/text/event-stream/ WebSocket 继续输出 - 网关、代理、前端请求方式有没有把流缓存掉
一句话说透这个坑
Flux 只说明你的后端代码里有流,不说明浏览器一定看到了流。
前端想真正一段一段收到内容,必须整条链路都支持”不要聚合、持续输出”。
Spring AI 里面到底是 Netty、Flux,还是 Reactor-会和 Spring WebMVC 冲突吗
这个问题特别典型,因为很多人会把这几个词当成同一层的东西。
其实它们分别属于不同层次:
Flux:是响应式流类型- Reactor:是 Spring WebFlux 背后的响应式库,
Flux和Mono就来自 Reactor - Netty:是一个网络通信框架/运行时实现,常被 WebFlux 或
WebClient选作底层 HTTP 客户端或服务器
所以更准确地说:
Spring AI 在”流式编程模型”这一层,核心是 Reactor 的 Flux;Netty 不是 Spring AI 流式能力的同义词,更不是必须项。
Spring AI 流式能力主要依赖的是 Reactor
Spring AI 官方文档对 ChatClient.stream() 的返回值写得很清楚,流式响应直接就是:
Flux<String>Flux<ChatResponse>Flux<ChatClientResponse>
这说明它在 Java 代码层面采用的是 Reactor 响应式抽象。
也就是说,开发者真正直接接触到的”流式接口”,通常不是 Netty API,而是:
Flux<String>
或者:
Flux<ChatResponse>
Spring AI Alibaba 在这一点上也是一致的,文档同样是以 Flux 作为流式输出的统一表达。
Netty 更像底层可选运行时,不是你必须手写的对象
在 Spring 体系里,真正负责发 HTTP 请求的常常是 WebClient。而 Spring Framework 官方文档明确说明,WebClient 底层可以接不同的 HTTP client 实现,比如:
- Reactor Netty
- JDK HttpClient
- Jetty Reactive HttpClient
- Apache HttpComponents
所以你可以理解成:
- Reactor/Flux 解决”怎么在代码里表达流”
- Netty/JDK HttpClient/Jetty 解决”底层 HTTP 请求到底由谁来跑”
这也是为什么很多人项目里明明在用 Spring AI 流式能力,但业务代码里几乎看不到 Netty。
那它会不会和 Spring WebMVC 冲突
不一定冲突,但要看你怎么搭。
Spring Framework 官方文档明确说过,spring-webmvc 和 spring-webflux 是可以共存的;应用通常可以只用其中一个,也可以在一些场景下同时使用,比如:
- Web 层还是 Spring MVC Controller
- 但 HTTP 客户端调用用了响应式的
WebClient
所以从框架层面说:
Spring AI 使用 Reactor / Flux,不等于你的整个应用必须全面切到 WebFlux,也不等于它天然和 Spring MVC 对立。
但这里有一个实际开发中的重要细节
Spring AI 官方实现说明里提到过几个很关键的点:
- 流式响应只通过 Reactive stack 支持
- 命令式应用如果要用流式能力,需要引入 Reactive stack,比如
spring-boot-starter-webflux - 非流式调用则又会涉及 Servlet stack
- 某些工具调用和普通调用路径里,本身仍然可能存在阻塞行为
这意味着:
- 你是 Spring MVC 项目,也依然可以接 Spring AI
- 但如果你要用
stream(),通常还是得把响应式这一套依赖带进来 - “能共存”不代表”整个链路从头到尾都天然非阻塞”
一句话说透这层关系
你可以把它记成:
- Spring AI 的流式抽象:Reactor
Flux - Spring AI 底层 HTTP 实现:可能是 Netty,也可能不是
- 你的 Web 接口层:可以是 WebFlux,也可以是 Spring MVC,但流式场景通常离不开 Reactive stack
所以真正该问的不是”Spring AI 到底是不是 Netty”,而是:
它在哪一层用 Reactor 表达流,底层 HTTP 客户端是谁选的,你的 Controller 最终又打算怎么把流发出去。
真正实战时该怎么选
如果你是做 MCP:
- 本地工具、桌面集成、IDE 插件优先考虑
stdio - 独立部署、远程服务、多客户端访问优先考虑
HTTP - 如果文档写的是旧版
SSE传输,要顺手确认它是不是已经迁移到Streamable HTTP
如果你是做 Spring AI Web 应用:
- 只是普通问答接口,用同步返回就够了
- 想做”字一个个往外冒”的聊天体验,就上流式输出
- 前端是浏览器时,
SSE往往是最省事的方案之一
开发者最该记住的,不是名词,而是分层思维
很多技术名词一旦同时出现在一个页面上,就特别容易把人绕晕。
但你真正开始做项目后会发现,工程里最值钱的能力,从来不是背住多少缩写,而是遇到一个概念时,先判断它到底属于哪一层。
比如:
uv、npm属于”服务怎么启动”stdio、SSE、HTTP属于”消息怎么传”Flux属于”代码里怎么表达流”- “流式输出” 属于”用户最终看到什么交互体验”
一旦你有了这个分层意识,很多原本看起来很玄乎的词,马上就会变得特别朴素。
你不会再问”Flux 是不是一种协议”,也不会再把”Spring AI 用了 SSE”理解成”它底层只能这么做”,更不会把”配置里用了 uv”误解成”这就是 MCP 的通信协议”。
真正成熟的工程判断,不是死记一个名词,而是先把它放回正确的层次里。
最后总结
这几个概念,最怕的不是多,而是混层。
uv、npm 说的是”怎么把 MCP Server 跑起来”;stdio、SSE、Streamable HTTP 说的是”跑起来以后怎么通信”;而 Spring AI 里的流式开发,说的是”内容是不是一段段持续返回”,SSE 只是它在 Web 场景里最常见的一种落地方式。
真正把层次分清后,你会发现这些名词根本不复杂:启动归启动,传输归传输,编程模型归编程模型,流式归交互体验。
延伸阅读
MCP 官方传输文档: https://modelcontextprotocol.io/docs/concepts/transports
MCP 2025-03-26 规范中的传输章节: https://modelcontextprotocol.io/specification/2025-03-26/basic/transports
Spring AI MCP 总览: https://docs.spring.io/spring-ai/reference/api/mcp/mcp-overview.html
Spring AI ChatClient 流式响应: https://docs.spring.io/spring-ai/reference/api/chatclient.html
Spring AI ChatModel 流式响应: https://docs.spring.io/spring-ai/reference/api/chatmodel.html
Spring AI OpenAI Chat: https://docs.spring.io/spring-ai/reference/api/chat/openai-chat.html
Spring Framework WebClient: https://docs.spring.io/spring-framework/reference/web/webflux-webclient.html
Spring Framework WebFlux: https://docs.spring.io/spring-framework/reference/web/webflux.html
Spring Framework Reactive Libraries: https://docs.spring.io/spring-framework/reference/web/webflux-reactive-libraries.html
Spring WebFlux 返回值与 text/event-stream:
https://docs.spring.io/spring-framework/reference/web/webflux/controller/ann-methods/return-types.html
MDN 关于 SSE: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
Spring Framework 关于 SseEmitter:
https://docs.spring.io/spring-framework/reference/web/webmvc/mvc-ann-async.html
OpenAI Streaming 官方文档: https://platform.openai.com/docs/guides/streaming
Spring AI Alibaba ChatClient: https://java2ai.com/integration/chatclient/
欢迎关注公众号 FishTech Notes,一块交流使用心得!